






Tribus Digital created the ‘Do You See What A.I. See?’ game using a method known as ‘VQGAN + CLIP’.
Two A.I. components communicate with one another in a trial and error process, , ‘VQGAN’ generates an image and ‘CLIP’ evaluates how closely the image represents its interpretation of what is required. This process runs over and over, each time further qualifying and improving the image. The video you see in the quiz is the result of this process, the final image reveals itself as the process improves the image over time.

A Muppets Christmas Carol
The neural network creates these images from a text prompt that includes a series of keywords and if needed, modifiers. At no stage is an existing image (from google, for example) being used, manipulated or ‘filtered’. Instead, the A.I. understands visual concepts having previously observed many images and is able to create new images based on the inputted phrase. This is a particularly exciting development as it marks an early milestone in the capability of A.I to be ‘creative’.
This method is the result of two papers written in the neural network and computer vision research space, namely: Taming Transformers for High-Resolution Image Synthesis (VQGAN) and Learning Transferable Visual Models From Natural Language Supervision (CLIP).
What is VQGAN?
Put simply, VQGAN can create images from a list of learned visual concepts. Initially, thousands of images are analysed for visual patterns at multiple levels of detail. In the very smallest details, the computer might recognise which individual coloured pixels are likely to appear together. While at the overall level where lines, curves and shapes might appear in the image. These concepts are stored in a kind of visual dictionary. To create an image the computer is able to reference this visual dictionary and combine concepts, for example: by looking at dogs, faces looking up, people drinking water and people surfing, the neural network is able to generate an image of a dog looking up, drinking water while surfing. Not by combining the original images, instead by understanding what is meant visually by each of the words individually, parts of the sentence and then the prompt as a whole.
VQGAN works in probabilities, for example it might be asking itself “in all of the pictures of dogs I have seen, how often has a green pixel appeared beside a brown pixel?” or “how often has a curved shape appeared toward the centre of the image compared to at the left edge?” By continuously interrogating these principles, over hundreds of iterations, the computer is able to output an image that represents the desired result.
A brief history of VQGAN
VQGAN or ‘Vector Quantized Generative Adversarial Network’ is a neural network image synthesis technique developed by researchers at Heidelberg University. Their unique double tiered approach to image perception, that enabled VQGAN to produce such impressive results, is the culmination of two individual approaches to computer vision. Firstly, research had been conducted in order to understand complex interactions between symbolic concepts within images such as in ‘Deep boltzmann machines’ in 2009 as well as ‘Neural variational inference and learning in belief networks’ in 2014 and ‘Neural discrete representation learning’ in 2017. This research provided a basis for ‘long range dependencies’ although it couldn’t yet be integrated into a useful image synthesis process.

Home Alone, Kevin McCallister
At the time, computer vision and image synthesis techniques focused on understanding the smaller relationships between pixels at a local level. One particular milestone, in 2017, proved that it is possible to predict local pixel interactions by restricting them to a ‘kernel’ using convolutional neural networks (CNN). This enabled the computer to build an image up from small areas of pixels which would grow into edges and eventually shapes.
How does VQGAN work?
By combining the above two approaches VQGAN is able to use computer vision to synthesize images recognisable by humans, using human concepts. However, some further development would have to take place in order to combine the concept of ‘long range dependencies’ with ‘convolutional neural networks (CNN)’. Throughout 2018, 2019 and 2020 researchers attempted to combine these approaches through the use of ‘transformers’, a common method of achieving ‘long range dependencies’ outside of image synthesis (in natural language processing, for example). This method mapped the patterns discovered by CNN into a ‘feature map’ of visual components before using transformers to interpret the individual visual features according to their ‘long range dependencies’.
However these attempts proved too demanding on computer hardware while simplifying image input data delivered unsatisfactory results. Instead, VQGAN makes use of ‘vector quantisation’ (VQ) which groups visual features into a ‘codebook’ first. This codebook operates like a dictionary of visual concepts summarising many smaller visual features and can interact with transformers, lessening their load and making operations compatible with current hardware capabilities.
This codebook can be thought of as a dictionary of words, for example, ‘frog’, ‘book’ and ‘dancing’ relating to their visual characteristics while the transformer can be thought of as how those words can work together, for example, ‘a frog reading a book while dancing’ or ‘a book about a dancing frog’.

Jingle All The Way Arnold Schwarzenegger
Further to this, VQGAN incorporates a ‘generative adversarial network’ (GAN). We can see how all of these components interact with one another in the below diagram. CNN is actually broken down and used throughout GAN, in a sense superseding CNN's original functionality.
GAN is a process consisting of a generator and a discriminator, the former creating an image while the latter verifies how likely that image is ‘correct’. Reading the diagram from left to right we can see that the image of the dog is summarised into the codebook according to the visual appearance of its nose, eye and the composition of the image as a whole. This would be done in much more detail and across thousands of images. The codebook is then used by both the transformer and the GAN to understand and interpret the image before the CNN can determine whether the outputted image is accurate or not.

What is CLIP?
To understand CLIP simply, think of it like this: A computer is given 1,000 images of cats and dogs, the images of cats are titled ‘cat’ and the images of dogs are titled ‘dog’. The computer breaks down each of those images into pieces and finds aspects of the image that are similar. The computer is then shown a new image of a cat or dog and is able to predict likelihood it is either a cat or dog based upon the similarities with the original dataset.

The Nightmare Before Christmas
CLIP operates using a model trained on imagery openly available on the internet. Think millions of images with hundreds of categories each. Where previously, datasets have been created manually (ImageNet, for example, took 25,000 workers to annotate 14 million images with 22,000 object categories.) CLIP opens up the potential of ‘computer vision’ as there is no reliance on ‘supervised learning’, the CLIP method now allows models to learn and expand freely without expensive and time consuming human bias.
A brief history of CLIP
CLIP or ‘Contrastive Image-Language Pretraining’, is a project by OpenAI that builds upon a large body of work dating back over a decade. It uses a method of ‘natural language supervision’ among other techniques, that allow the model to learn categories and descriptions in such detail that it can accurately understand concepts to which it was not previously exposed to.
Researchers at Stanford developed a proof of concept in 2013, showing that a model trained on the CIFAR-10 dataset could predict ‘unseen classes’. Later that year, DeVISE advanced the approach using an ImageNet model that could correctly predict images outside of the 1,000 original images in the training dataset. More recently, in 2016, FAIR fine tuned an ImageNet CNN to predict ‘visual n-grams’ - more accurately breaking down images into their components. In 2021 these methods have been updated to cooperate with modern architectures like the ‘Transformers’ used in VQGAN. The field now includes projects that investigate more complex language descriptions such as ‘autoregressive language modelling’ and ‘masked language modelling’. One project ‘ConVIRT’ uses the method for medical image classification, advancing the ability of doctors to diagnose visual symptoms.
How does CLIP work?
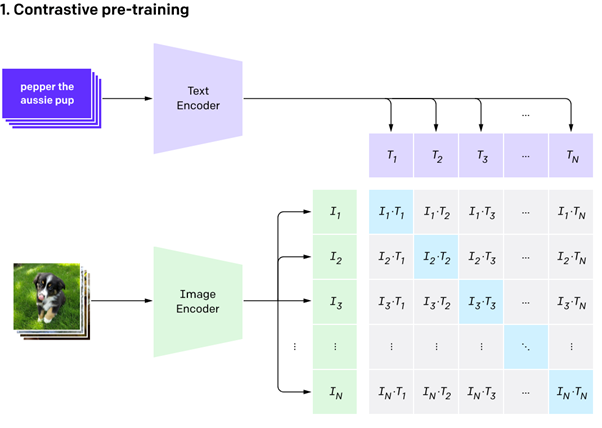
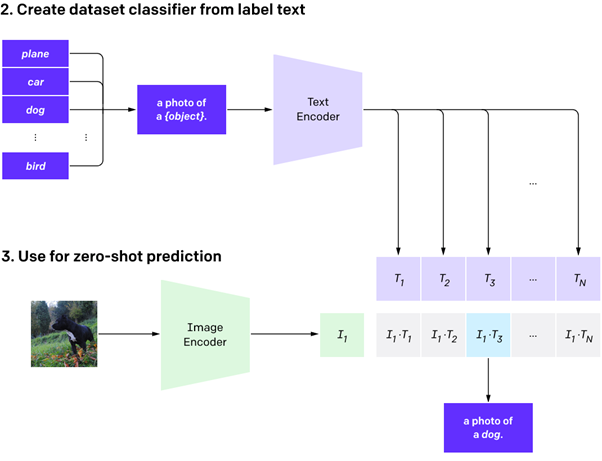
We can see how these advancements have allowed the method to become extremely flexible in the below example. In ‘contrastive pre-training’ (1) the model has taken the text ‘pepper the aussie pup’ associated with the image of a dog and broken both the text and image down into pieces or ‘n-grams’. An n-gram might be ‘aussie pup’, ‘pup’, ‘pepper the aussie’ or any other way of breaking down that sentence. Similarly the image is broken down into its constituent parts; the foreground, the background, the fur, a ‘furry foreground on a grassy background’, etc. This is done with thousands of images and titles. Following this the model will ‘create a dataset classifier from the label text’ (2), i.e. summarise the original text by comparing its similarity to a continuously updated generalised list of labels. Here the model is asking itself “does ‘pepper the aussie pup’ mean ‘bird’ or ‘dog’?” FInally the model is able to ‘use zero shot prediction’ (3) to look at a new image, again, breaking it down into ‘n-grams’ and comparing them to what it has learned in training to correctly classify ‘a photo of a dog’.
CLIP is not task-specific, it is optimised toward achieving human-like visual recognition. Where other A.I. projects might achieve more impressive results in, for example, recognising the distance of an obstacle from a car or counting the number of identical objects in an instant, CLIP achieves only a little better than a random selection in these areas. CLIP is instead much more capable in understanding visual concepts and following natural language instructions.
Why?
You score points in ‘Do you see what A.I. see?’ by correctly guessing the film title on which the prompt was based, achieving this quickly is rewarded with more points. Unlike task-specific artificial intelligence projects that optimise to perform one operation very well, both VQGAN and CLIP were developed to be as open and human-like in their perception as possible. What we found interesting in this project (and the process in general) is how the neural network can create infinite images from the same prompt, all slightly different, most often without containing a single, definable object in the image yet there is a strange familiarity to the image that allows you to recognise it. It’s at this intersection that we can see in a purely visual, yet still fairly primitive way, how computers are interpreting the very way we as humans endow things and concepts with meaning.
The game pits human perception against machine perception in a novel way to highlight how close artificial intelligence is to human intelligence in the closing days of 2021.
Sources:
https://ljvmiranda921.github.io/notebook/2021/08/08/clip-vqgan/
https://arxiv.org/abs/2103.00020


